一.介紹
日常生活中,娛樂是不可或缺的,電影是現今大家常談起的,什麼電影要上映、有哪位卡司有演、劇情會如何……各種原因都會影響到民眾對此部電影的評價,IMDb作為網路上電影資料庫,裏頭有豐富的電影作品資訊且對各電影的評價,我們將其作為依據來進行分析。
我們以現有資料對IMDb的評分分為二類和三類,再使用對4種機器學習的方式(Random Forest、SVM、Adaboost、Decision tree)進行分析,並以迴歸和逐步迴歸的形式挑選變數,何種機器學習成效較高?
三.結果簡述
在實驗結果中我們發現分二類與三類的情況,Random Forest的正確率最高,最高正確率三類可達到70%;二類可達到83%。Decision tree和SVM的正確率偏低,最低正確率三類只有54%;二類只有73%。
四.變數介紹
Data源自於Kaggle中的IMDb 5000 movie,有28個變數,經過整理與轉換後使用近四千筆來進行分析,實際上使用21個變數,有類別變數與連續變數。
0
|
1
|
2
|
|
Color 色彩
|
黑白:124
|
彩色:3641
|
x
|
language語言
|
others:159
|
English:3606
|
x
|
Country 國家
|
others:456
|
USA:2992
|
UK:317
|
content_rating
電影分級
|
17歲以下:2053
|
17歲以上:1712
|
x
|
genres 電影風格
|
|
1:Comedy喜劇
|
1227
|
2:Action動作
|
962
|
3:Adventure 冒險
|
391
|
4:Animation 動畫為
|
45
|
5:Biography 傳記
|
213
|
6:Crime 犯罪
|
257
|
7: Documentary
紀錄片
|
31
|
8:Drama 劇情
|
673
|
9:Family 家庭
|
3
|
10:Fantasy 奇幻
|
37
|
11:Horror 恐怖
|
164
|
12:Musical 音樂
|
2
|
13:Mystery 神秘
|
23
|
14:Romance 浪漫
|
1
|
15:Sci-Fi 科幻
|
7
|
16:Thriller 驚悚
|
1
|
17:Western 西部
|
3
|
連續變數
Mean
|
Var
|
Min
|
Max
|
|
num_critic_for_reviews 評論評級
|
167
|
123.5748
|
1
|
813
|
duration 片長
|
110.2
|
22.62464
|
37
|
330
|
director_facebook_likes 導演FB like 數
|
805.1
|
3064.794
|
0
|
23000
|
actor_3_facebook_likes 演員3 FB like 數
|
769.6
|
1892.301
|
0
|
23000
|
actor_1_facebook_likes 演員1 FB like 數
|
7731
|
15505.22
|
0
|
640000
|
gross 票房
|
52420000
|
70271383
|
162
|
760500000
|
num_voted_users IMDB用戶評分數
|
105400
|
151843.7
|
22
|
1690000
|
ast_total_facebook_likes 卡司FB like 數
|
11500
|
19105.07
|
0
|
656700
|
facenumber_in_poster 海報上人臉數
|
1.377
|
2.041313
|
0
|
43
|
num_user_for_reviews IMDB用戶評論數
|
335.9
|
411.1153
|
1
|
5060
|
budget 預算
|
4.612e+07
|
225749219
|
2.180e+02
|
1.222e+10
|
title_year 上映年份
|
2003
|
90885925
|
1927
|
2016
|
actor_2_facebook_likes
演員2 FB like 數
|
2015
|
4538.057
|
0
|
137000
|
imdb_score IMDB分數
|
6.463
|
1.057508
|
1.6
|
9.3
|
aspect_ratio 電影寬高比
|
2.112
|
0.35287
|
1.18
|
16
|
movie_facebook_likes 電影FB like數
|
9333
|
2442.68
|
0
|
349000
|
未使用變數
1. Director_name 導演名稱。
2. actor_2_name 演員2名字
3. actor_1_name 演員1名字。
4. movie_title 電影名稱。
5. actor_3_name 演員3名字。
6. plot_keywords 章節關鍵字。
7.
movie_imdb_link
電影IMDb網址。
五.方法與結果
三千多筆資料我們以IMDb的評分分成二類與三類,二類分成分數前50%與後50%,臨界點為6.6分在此分數上較出名的電影為《納尼亞傳奇:賈斯潘王子》(The Chronicles of Narnia: Prince Caspian)、《飢餓遊戲:自由幻夢 終結戰》(The Hunger
Games: Mockingjay - Part 2)。
三類分成IMDb分數從小到大的第33%的臨界點為6.1分,如《超人再起》(Superman Returns)、《MIB星際戰警2》(Men in Black II);第66%的臨界點 7分,如《蜘蛛人:驚奇再起》(The Amazing Spider-Man )、《末日之戰》(World
War Z)
分數評分前三名的電影分別是1974年上映的災難電影評分9.5分《火燒摩天樓》(Towering Inferno)、1994年上映的小說改編電影評分9.3分《刺激1995》(The Shawshank Redemption) 和1978年上映的犯罪電影評分9.2分《教父》(The Godfather)。
以下為隨機挑選70%筆資料做Training data,30%筆資料做Testing data,並同時用4種方式(RF、SVM、Adaboost、Decision tree)進行分析,且做十次後結果平均。(使用程式為R語言及Python確認程式結果)
a. 變數未轉換
b. 連續、類別皆標準化
c. 連續未轉換、有類別變數
d. 連續標準化、有類別變數
Step1. Data不做轉換
二類
|
RF
|
SVM
|
AD
|
TREE
|
a.
|
80%
|
73.7%
|
77.6%
|
75.3%
|
b.
|
78.9%
|
74.2%
|
78.5%
|
76%
|
c.
|
79.2%
|
74.6%
|
78.4%
|
75.7%
|
d.
|
80.3%
|
75.9%
|
80%
|
76.1%
|
三類
|
RF
|
SVM
|
AD
|
TREE
|
a.
|
67%
|
62.2%
|
63.1%
|
54.3%
|
b.
|
66.6%
|
62.6%
|
62.6%
|
54.9%
|
c.
|
66.1%
|
62.1%
|
62.9%
|
55.1%
|
d.
|
67.3%
|
63.1%
|
63.3%
|
55.3%
|
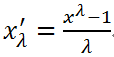
gross : λ = 0.24717826683381774
budget : λ = 0.24889626975601842
aspect_ratio : λ = -0.13149883961948991
budget : λ = 0.24889626975601842
aspect_ratio : λ = -0.13149883961948991
二類
|
RF
|
SVM
|
AD
|
TREE
|
a.
|
82%
|
79.8%
|
80.1%
|
75.3.%
|
b.
|
80.7%
|
78.3%
|
79.7%
|
76.5%
|
c.
|
78.8%
|
77.9%
|
80.1%
|
76.9%
|
d.
|
79.1%
|
78.8%
|
80.2%
|
77.1%
|
三類
|
RF
|
SVM
|
AD
|
TREE
|
a.
|
68.1%
|
63.9%
|
62.5%
|
56.5%
|
b.
|
67.1%
|
62.6%
|
63%
|
56.8%
|
c.
|
67.5%
|
63.6%
|
62.6%
|
56.3%
|
d.
|
67.6%
|
64.9%
|
63.3%
|
57%
|
Step3. Data做逐步迴歸20個→17個解釋變數(num_critic_for_reviews、duration、actor_1_facebook_likes、gross、genres、num_voted_users、cast_total_facebook_likes、facenumber_in_poster、num_user_for_reviews、language、country、content_1ating、budget、 title_year、actor_2_facebook_likes、aspect_ratio、movie_facebook_likes)
共去除 color、director_facebook_likes、actor_3_facebook_likes
二類
|
RF
|
SVM
|
AD
|
TREE
|
a.
|
82.4%
|
79.8%
|
82%
|
73.8%
|
b.
|
82.4%
|
79.5%
|
81.1%
|
73.9%
|
c.
|
82.1%
|
79.3%
|
80.7%%
|
74.1%
|
d.
|
82.7%
|
79.6%
|
82.2%
|
74.3%
|
三類
|
RF
|
SVM
|
AD
|
TREE
|
a.
|
69.1%
|
65.6%
|
65.6%
|
58.5%
|
b.
|
68.9%
|
65.7%
|
66.2%
|
57.7%
|
c.
|
68.7%
|
65.1%
|
65%
|
58.1%
|
d.
|
69.9%
|
66.3%
|
66%
|
58.9%
|
六.結論
整理數據時發現預算及票房的變數有誤,美金和其他貨幣並沒有統一,因此我們有將其貨幣轉成美金為單位,原本我們預想IMDb分數會和票房及預算非常相關,但在第一步模型中挑選較不顯著的變數中這兩個都被挑出來,也許是因為幣值或是電影前期成本並不像現今這麼高成本(例如:通貨膨脹)。使用Box-Cox將不顯著的數據做轉換後,結果顯示無論是二類或三類正確率上升幅度不明顯,但各項實驗皆有上升1~2%的趨勢。
第三步驟我們將較不重要的變數挑選出來,再做一次實驗發現比起第二步驟也是上升了1~2%左右,也代表說本數據做逐步迴歸下也是有將正確率提升的效果。
本實驗中也有將類別變數獨立出來和不獨立出來做研究,發現若將類別變數獨立出來做的4種方法預測正確率大部分都小於全部變數當成連續變數的正確率,代表本數據在做「混和型」的變數上並不顯著,無論是在哪個方法中皆無表現好的。若將連續變數做標準化是有將預測正確率提升的功用,都有上升1個百分點的趨勢,因此在「變數標準化」是有效果的。
在上面表格中可以明顯發現Decision tree的正確率是最低的,無論是二類或三類的正確率都與其他方法差10%左右。分二類中Random Forest與AdaBoost兩種方法不相上下,正確率也都差不多,但在分三類中兩者方法Random Forest比起AdaBoost高了大概4%左右的正確率。因此我們在這個研究中可以知道對於IMDb的預測Random Forest>AdaBoost>SVM>Decision tree。
在我們的預測當中,二類82%以及三類的70%,此表現可否預測一部電影的好壞,還有商討的空間。但 Netflix Prize 也有辦過預測電影的比賽,懸賞獎金100萬美元,花了3年才有人把獎金領走,說明預測電影是一件非常難的事情,並不是大眾想的這麼簡單。
七.Code
######R########
data=read.csv("C:/Users/user/Desktop/moviedata8.csv",header=T);
attach(data)
library(e1071)
#變數數量r
r=18
## CV
index = 1:nrow(data)
index.1 = sample(index, trunc(length(index)/3))
index.2 = sample(index[-index.1],
ceiling(length(index)/3))
index.3 = sample(index[-c(index.1,index.2)])
list.index = list(index.1,index.2,index.3)
i = 1
x.train = data[unlist(list.index[-i]),]
x.test = data[list.index[[i]],]
# RF
library(randomForest)
rf = randomForest(x = x.train[,-r],y =
as.factor(x.train[,r]),importance = T,ntree = 1000,mtry = 3)
importance(rf)
train = predict(rf,x.train[,-ncol(x.train)])
test = predict(rf,x.test[,-ncol(x.test)])
# training data misclassification table
t1 = table(true = x.train[,ncol(x.train)] , pred =
train)
train.table = cbind(t1,class_error =
round(1-diag(t1)/rowSums(t1),3))
show(train.table)
train.error = round(1-sum(diag(t1))/sum(t1),3)
show(train.error)
# testing data misclassification table
t2 = table(true = x.test[,ncol(x.test)] , pred =
test)
test.table = cbind(t2,class_error =
round(1-diag(t2)/rowSums(t2),3))
show(test.table)
test.error = round(1-sum(diag(t2))/sum(t2),3)
show(test.error)
## SVM
library(e1071)
s.trainset = scale(x.train[,-r])
mean = attr(s.trainset,"scaled:center")
var = attr(s.trainset,"scaled:scale")
s.testset = t((t(x.test[,-r])-mean)/var)
svm.ML = svm(y = as.factor(x.train[,r]), x =
s.trainset ,type = "C-classification", probability = T)
train = predict(svm.ML, s.trainset)
test = predict(svm.ML, s.testset)
# training data misclassification table
t1 = table(true = x.train[,ncol(x.train)] , pred =
train)
train.table = cbind(t1,class_error = round(1-diag(t1)/rowSums(t1),3))
show(train.table)
train.error = round(1-sum(diag(t1))/sum(t1),3)
show(train.error)
# testing data misclassification table
t2 = table(true = x.test[,ncol(x.test)] , pred =
test)
test.table = cbind(t2,class_error =
round(1-diag(t2)/rowSums(t2),3))
show(test.table)
test.error = round(1-sum(diag(t2))/sum(t2),3)
show(test.error)
### AdaBoost
library(adabag)
boosting.ML <- boosting(y~., data=
data.frame(s.trainset , y = as.factor(x.train[,r])), mfinal = 300)
train = predict(boosting.ML,
data.frame(s.trainset, y = as.factor(x.train[,r])))
test = predict(boosting.ML, data.frame(s.testset,
y = as.factor(x.test[,r])))
# training data misclassification table
t1 = table(true = x.train[,ncol(x.train)] , pred =
train$class)
train.table = cbind(t1,class_error =
round(1-diag(t1)/rowSums(t1),3))
show(train.table)
train.error = round(1-sum(diag(t1))/sum(t1),3)
show(train.error)
# testing data misclassification table
t2 = table(true = x.test[,ncol(x.test)] , pred =
test$class)
test.table = cbind(t2,class_error =
round(1-diag(t2)/rowSums(t2),3))
show(test.table)
test.error = round(1-sum(diag(t2))/sum(t2),3)
show(test.error)
#下面建立訓練資料的決策樹
data.tree= rpart(imdb_score
~.,method="class",data=data.traindata)
data.tree
plot(data.tree);text(data.tree)#畫出決策樹
summary(data.tree)
#install.packages("gmodels")
library(gmodels)
cat("======訓練資料======","\n")
imdb_score.traindata=data$imdb_score[-test.index]
train.predict=factor(predict(data.tree,
data.traindata, type="class"), levels=levels(imdb_score.traindata))
CrossTable(x = imdb_score.traindata, y =
train.predict, prop.chisq=FALSE) #畫出CrossTable
train.corrcet=sum(train.predict==imdb_score.traindata)/length(train.predict)#訓練資料之正確率
cat("訓練資料正確率",train.corrcet*100,"%\n")
cat("======測試資料======","\n")
imdb_score.testdata=data$imdb_score[test.index]
test.predict=factor(predict(data.tree,
data.testdata, type="class"), levels=levels(imdb_score.testdata))
CrossTable(x = imdb_score.testdata, y =
test.predict, prop.chisq=FALSE) #畫出CrossTable
test.correct=sum(test.predict==imdb_score.testdata)/length(test.predict)#測試資料之正確率
cat("測試資料正確率",test.correct*100,"%\n")
#######Python#######
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import
RandomForestClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix
from scipy.stats import boxcox
from sklearn.model_selection import
train_test_split
from sklearn.preprocessing import scale
import time
import pandas as pd
names=['imdb_score', 'color',
'num_critic_for_reviews', 'duration', 'director_facebook_likes',
'actor_3_facebook_likes'
,
'actor_1_facebook_likes', 'gross', 'genres', 'num_voted_users',
'cast_total_facebook_likes', 'facenumber_in_poster'
,
'num_user_for_reviews', 'language', 'country', 'content_1ating', 'budget',
'title_year', 'actor_2_facebook_likes'
,
'aspect_ratio', 'movie_facebook_likes','imdb_score_3']
data =
pd.read_csv('C:/Users/wilson.408-PC/Desktop/IMDB/moviedata2.csv',sep =
',',encoding = 'utf-8',names=None)
data['imdb_score']=boxcox(data['imdb_score'])[0]
data['budget']=boxcox(data['budget'])[0]
data['gross']=boxcox(data['gross'])[0]
data['aspect_ratio']=boxcox(data['aspect_ratio'])[0]
#data['title_year']=data['title_year']-2000
#data['gross']=scale(data['gross'])
#data['budget']=scale(data['budget'])
array = data.values
arg=[1,2,4,5,6,8,9,10,11,12,13,14,15,16,17,18,20]
#逐步挑選的變數
X = array[:,arg]
Y = array[:,0]
X_train, X_test, Y_train, Y_test =
train_test_split(X, Y, test_size=0.3, random_state=7)
Y_train = Y_train.reshape((-1, 1))
Y_test = Y_test.reshape((-1, 1))
#machine learning
def svc(traindata,trainlabel,testdata,testlabel):
start_time = time.time()
print("Start training SVM...")
svcClf =
SVC(C=1,kernel="rbf",cache_size=1000)
svcClf.fit(traindata,trainlabel)
pred_trainlabel = svcClf.predict(traindata)
pred_testlabel = svcClf.predict(testdata)
confusionmatrix = confusion_matrix(testlabel,pred_testlabel)
print(confusionmatrix)
num_train = len(pred_trainlabel)
accuracy_train = len([1 for i in range(num_train) if
trainlabel[i]==pred_trainlabel[i]])/float(num_train)
print("%s : %.3f%%" % ('accuracy_train',accuracy_train*100))
num_test
= len(pred_testlabel)
accuracy_test = len([1 for i in range(num_test) if
testlabel[i]==pred_testlabel[i]])/float(num_test)
print("%s : %.3f%%" % ('accuracy_test',accuracy_test*100))
print(" %s m %.3f s " % (int((time.time() -
start_time)/60),(time.time() - start_time)%60))
print
def rf(traindata,trainlabel,testdata,testlabel):
start_time = time.time()
print("Start training Random Forest...")
rfClf =
RandomForestClassifier(n_estimators=1000,criterion='gini')
rfClf.fit(traindata,trainlabel)
pred_trainlabel
= rfClf.predict(traindata)
pred_testlabel = rfClf.predict(testdata)
confusionmatrix = confusion_matrix(testlabel,pred_testlabel)
print(confusionmatrix)
num_train = len(pred_trainlabel)
accuracy_train = len([1 for i in range(num_train) if
trainlabel[i]==pred_trainlabel[i]])/float(num_train)
print("%s : %.3f%%" % ('accuracy_train',accuracy_train*100))
num_test
= len(pred_testlabel)
accuracy_test = len([1 for i in range(num_test) if
testlabel[i]==pred_testlabel[i]])/float(num_test)
print("%s : %.3f%%" % ('accuracy_test',accuracy_test*100))
print(" %s m %.3f s " % (int((time.time() -
start_time)/60),(time.time() - start_time)%60))
print
def
AdaBoost(traindata,trainlabel,testdata,testlabel):
start_time = time.time()
print("Start training AdaBoostClassifier...")
AdaBoostClf = AdaBoostClassifier(n_estimators=1000)
AdaBoostClf.fit(traindata,trainlabel)
pred_trainlabel = AdaBoostClf.predict(traindata)
pred_testlabel = AdaBoostClf.predict(testdata)
confusionmatrix = confusion_matrix(testlabel,pred_testlabel)
print(confusionmatrix)
num_train = len(pred_trainlabel)
accuracy_train = len([1 for i in range(num_train) if
trainlabel[i]==pred_trainlabel[i]])/float(num_train)
print("%s : %.3f%%" % ('accuracy_train',accuracy_train*100))
num_test
= len(pred_testlabel)
accuracy_test = len([1 for i in range(num_test) if
testlabel[i]==pred_testlabel[i]])/float(num_test)
print("%s : %.3f%%" % ('accuracy_test',accuracy_test*100))
print(" %s m %.3f s " % (int((time.time() -
start_time)/60),(time.time() - start_time)%60))
print
def
DecisionTrees(traindata,trainlabel,testdata,testlabel):
start_time = time.time()
print("Start training DecisionTreeClassifier...")
treeClf
= DecisionTreeClassifier()
treeClf.fit(traindata,trainlabel)
pred_trainlabel = treeClf.predict(traindata)
pred_testlabel =
treeClf.predict(testdata)
confusionmatrix = confusion_matrix(testlabel,pred_testlabel)
print(confusionmatrix)
num_train = len(pred_trainlabel)
accuracy_train = len([1 for i in range(num_train) if
trainlabel[i]==pred_trainlabel[i]])/float(num_train)
print("%s : %.3f%%" % ('accuracy_train',accuracy_train*100))
num_test
= len(pred_testlabel)
accuracy_test = len([1 for i in range(num_test) if
testlabel[i]==pred_testlabel[i]])/float(num_test)
print("%s : %.3f%%" % ('accuracy_test',accuracy_test*100))
print(" %s m %.3f s " % (int((time.time() - start_time)/60),(time.time()
- start_time)%60))
print
def machine_learning(method):
method(X_train,
Y_train, X_test, Y_test)
'''
machine_learning(svc)
machine_learning(rf)
machine_learning(AdaBoost)
machine_learning(DecisionTrees)
'''
八.參考資料
沒有留言:
張貼留言